DeepSeek DSpark
Le décodage spéculatif qui rend les LLM 85 % plus rapides
Sans toucher aux poids · Open source · MIT
📖 Sommaire
↓ Cliquez sur un thème pour y accéder directement ↓
🚀 DSpark – le déclic inattendu
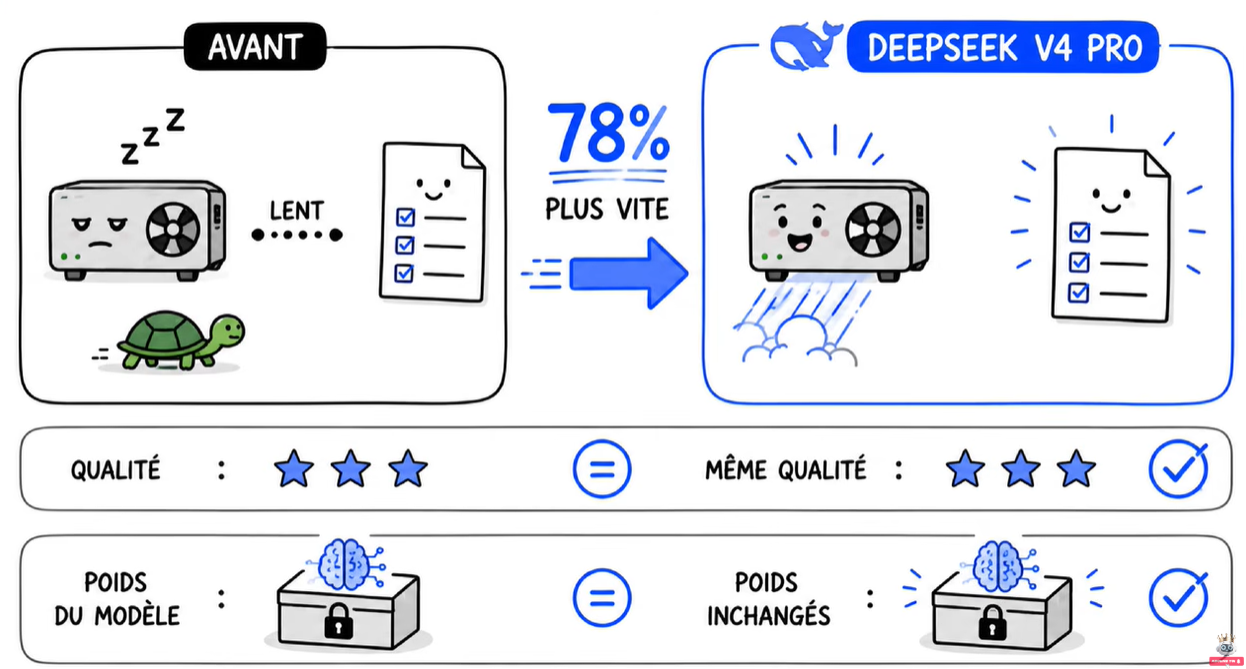
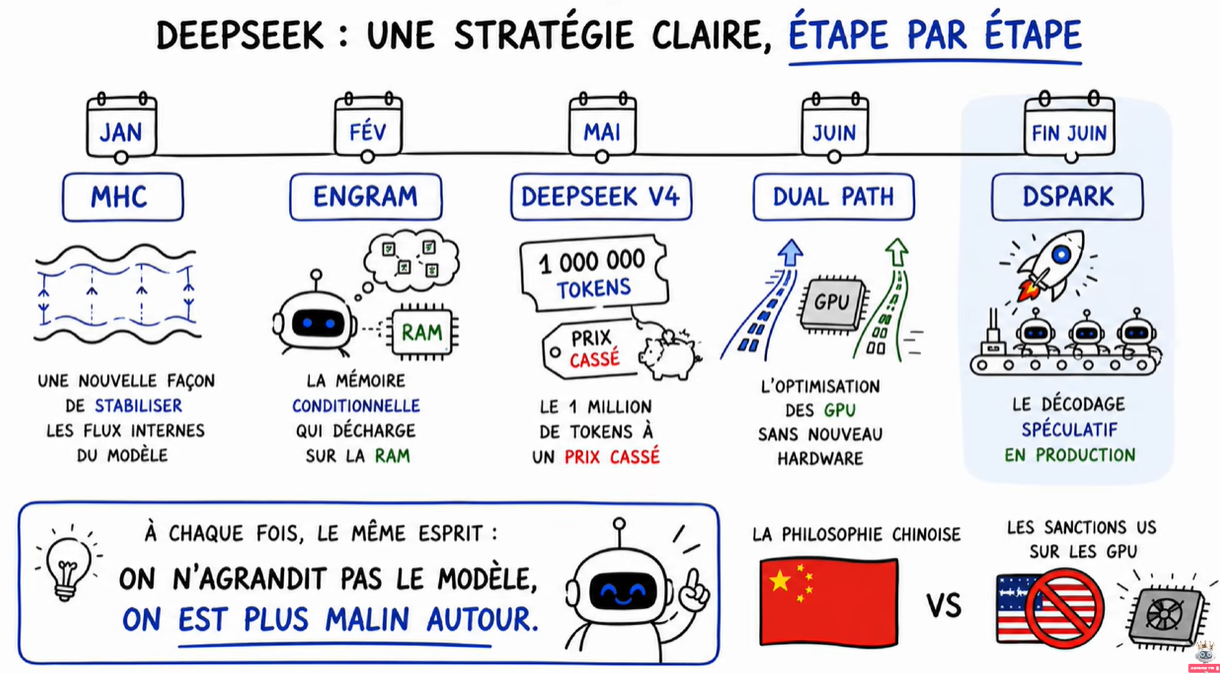
C’est la 5e fois en 6 mois que DeepSeek nous fait le coup de « on optimise au lieu d’agrandir ». La philosophie est toujours la même : on n’agrandit pas le modèle, on le rend juste plus malin. C’est la stratégie chinoise face aux sanctions américaines sur les GPU.
🔄 Pourquoi les LLM sont lents de base
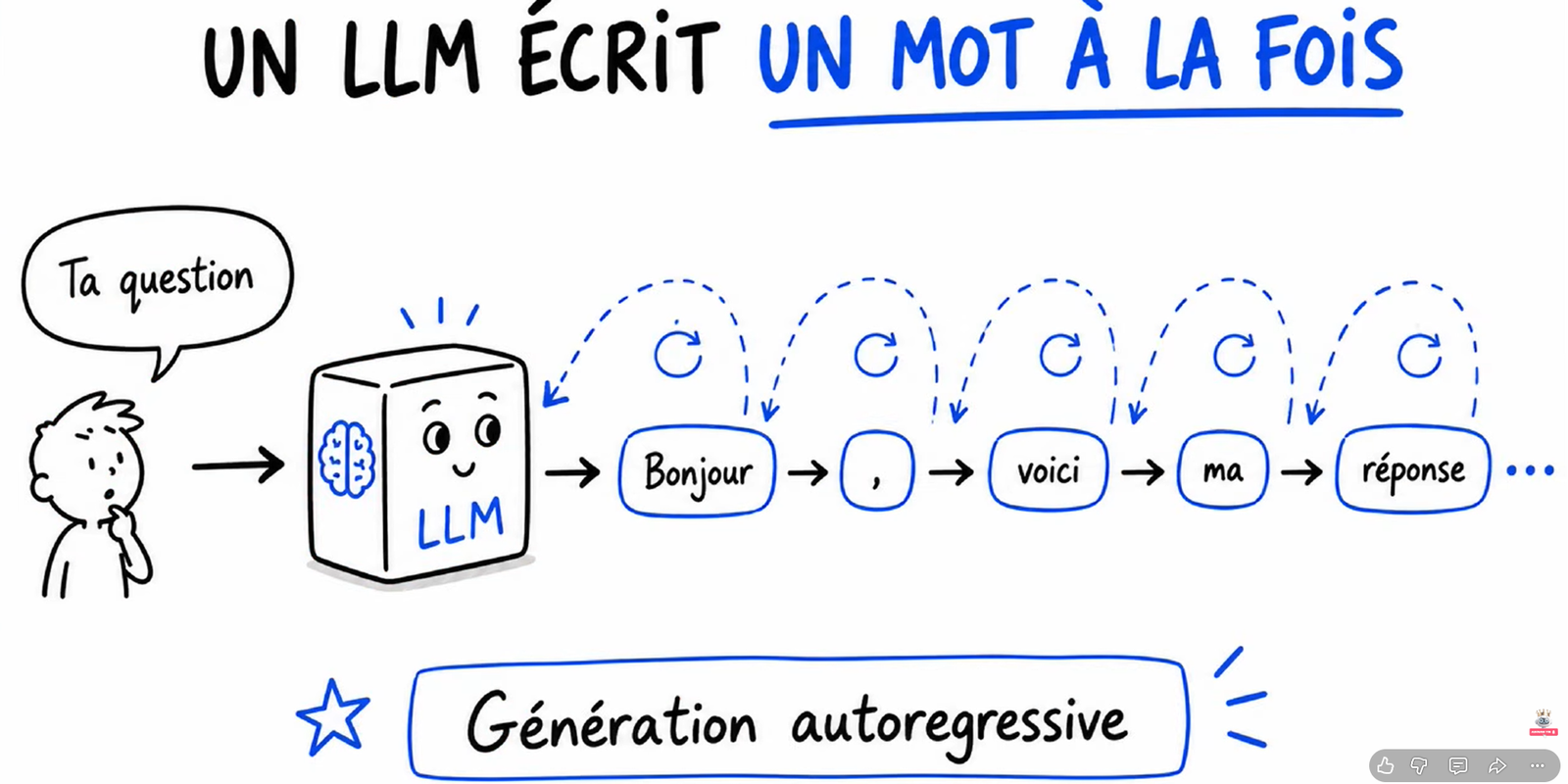
Concrètement : le modèle génère le premier mot, il regarde ce qu’il vient de produire, il génère le deuxième mot, il regarde encore, puis le troisième, et ainsi de suite. Pour générer chaque nouveau mot, le modèle doit relire toute sa mémoire interne (le fameux KV cache).
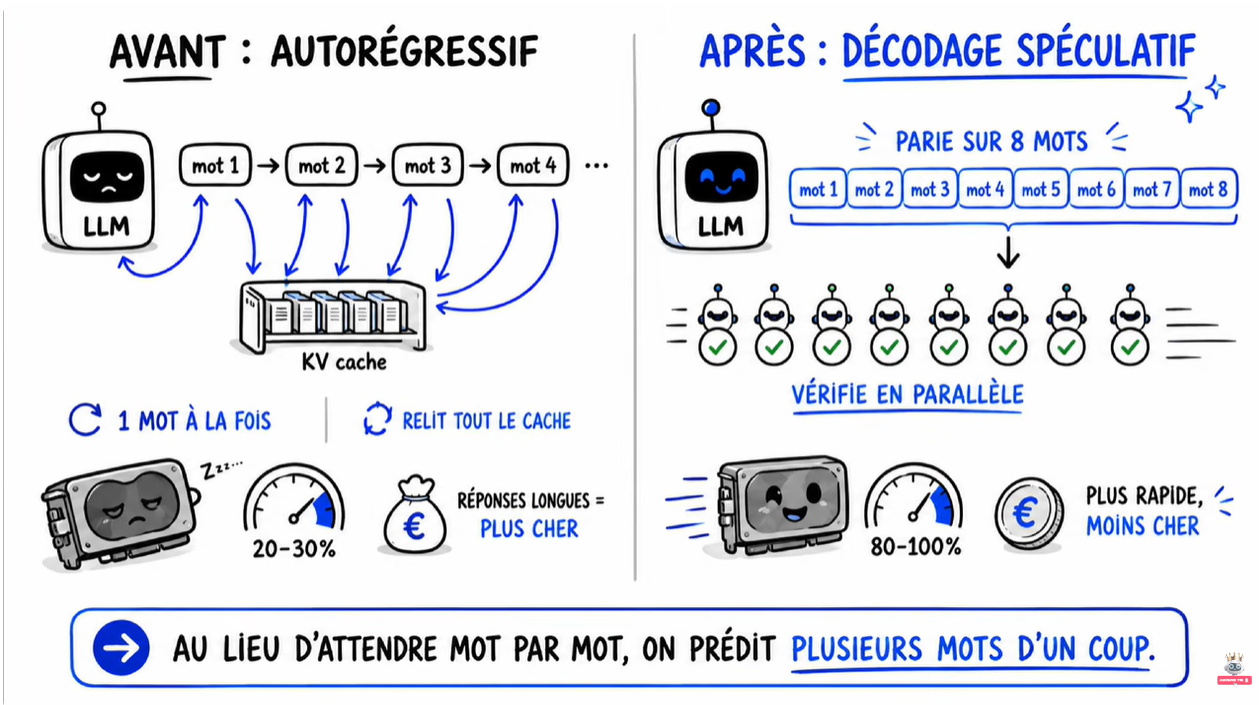
Le truc pervers : le décode représente 95 % du temps de vie d’une requête. Pour une réponse de 300 tokens, c’est 20 millisecondes de préfil contre 9 secondes de décode. Tu payes des H100 au prix de l’or pour qu’ils se tournent les pouces la quasi-totalité du temps.
🧠 Le décodage spéculatif – le petit propose, le gros vérifie
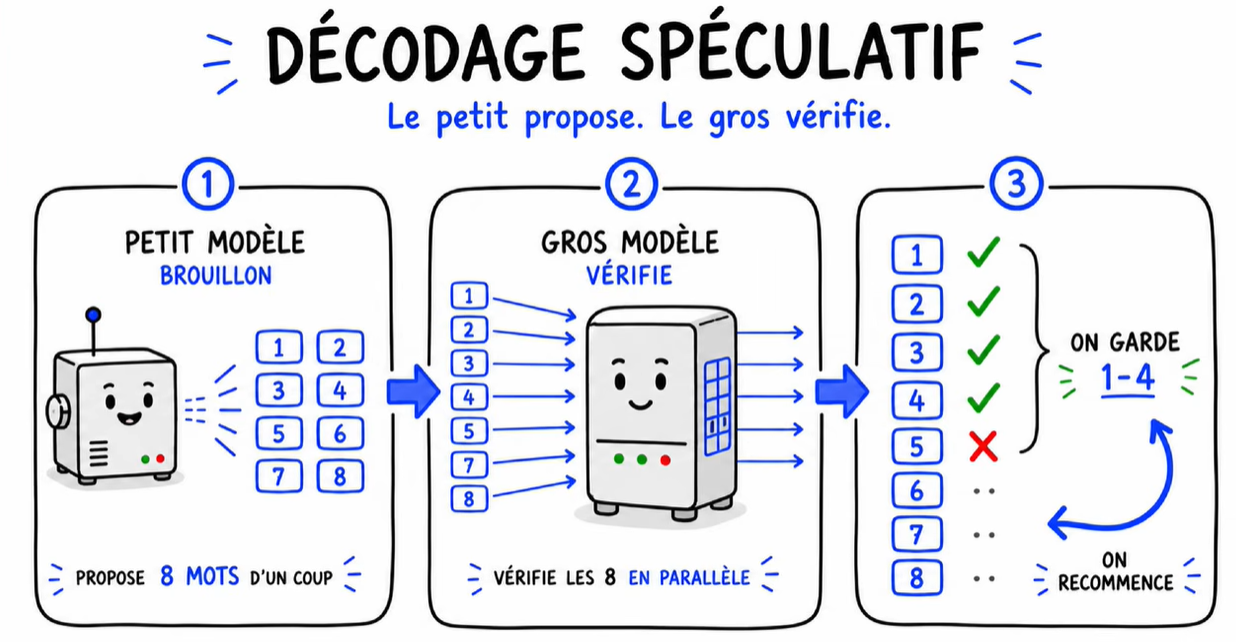
Tu prends deux modèles :
- Un gros ultra-puissant – c’est ton modèle cible, celui qui te répond habituellement.
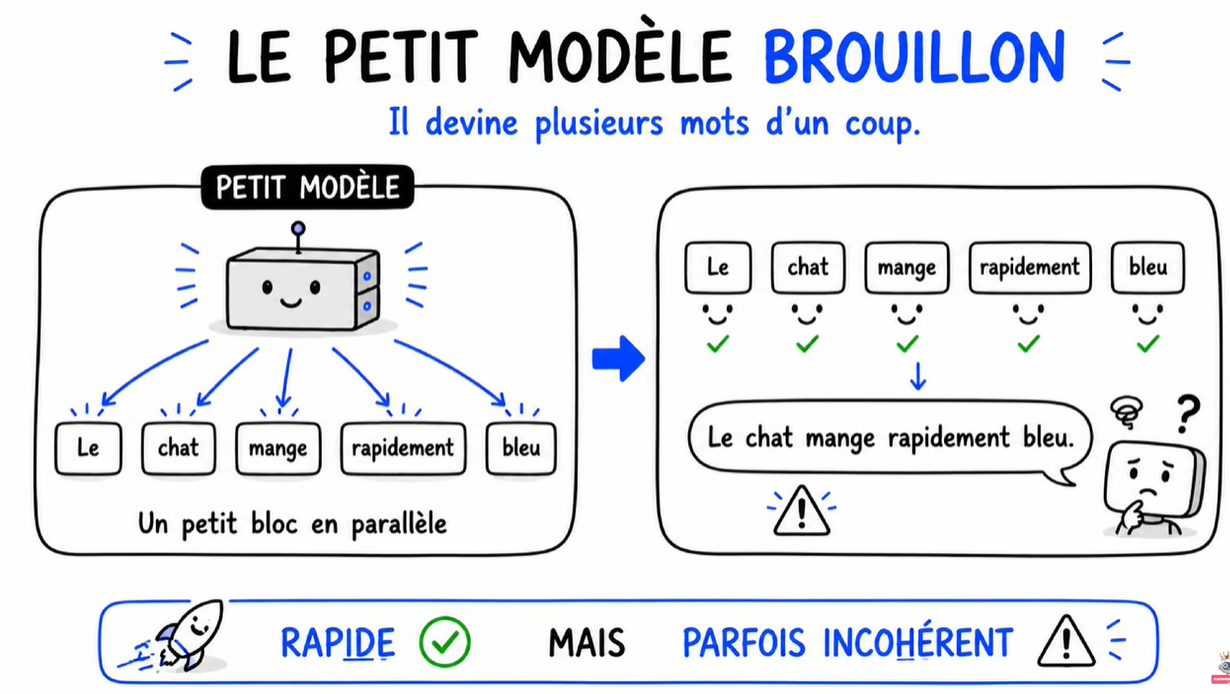
- Un petit modèle beaucoup plus rapide – qui va être ton modèle brouillon.
Le petit modèle propose une rafale de mots (genre 8 d’un coup). Le gros modèle, au lieu de les générer un par un, vérifie les 8 propositions en une seule passe parallèle. Si ça valide, c’est gagné : tu as généré 8 mots pour le prix d’un.
↺ Retour au sommaire⚖️ Deux approches, deux problèmes
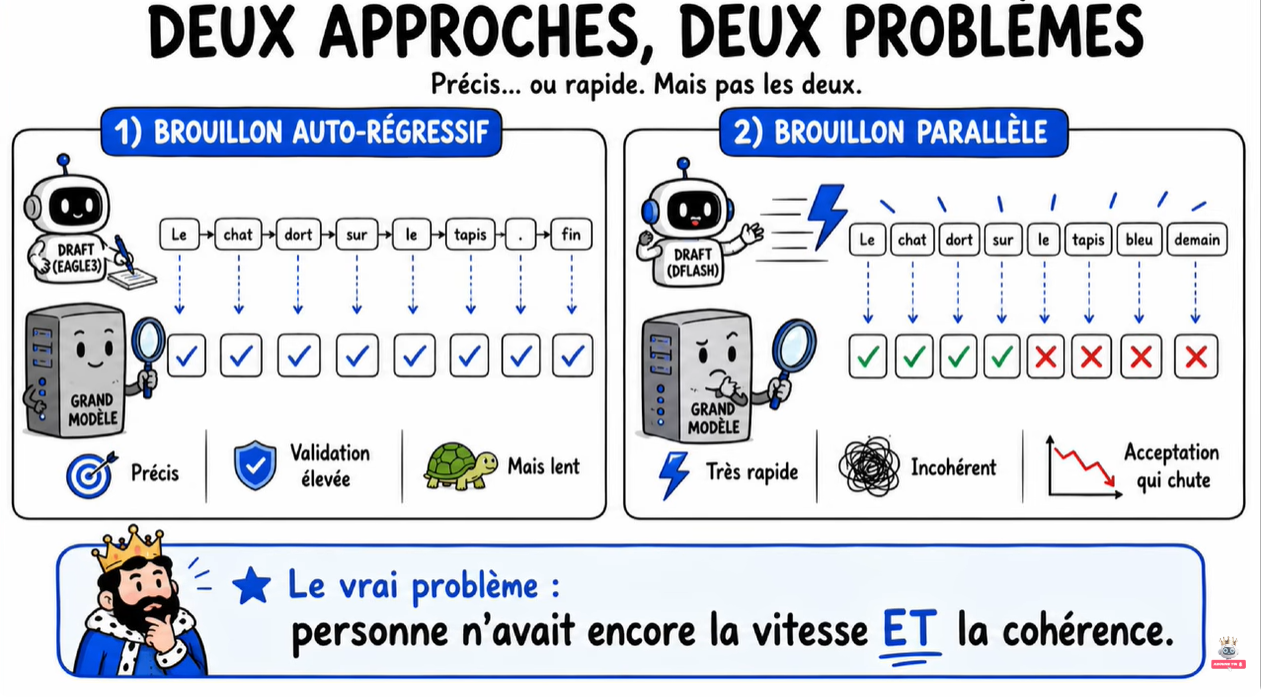
- Approche autorégressive (Eagle3) : précise, mais le brouillon prend du temps. Tu gagnes d’un côté, tu perds de l’autre.
- Approche parallèle (DFlash) : ultra-rapide, mais chaque mot est généré sans regarder ses voisins → incohérence → taux d’acceptation qui s’effondre sur les derniers mots du bloc.
🔗 La tête de Markov – le brouillon devient plus malin
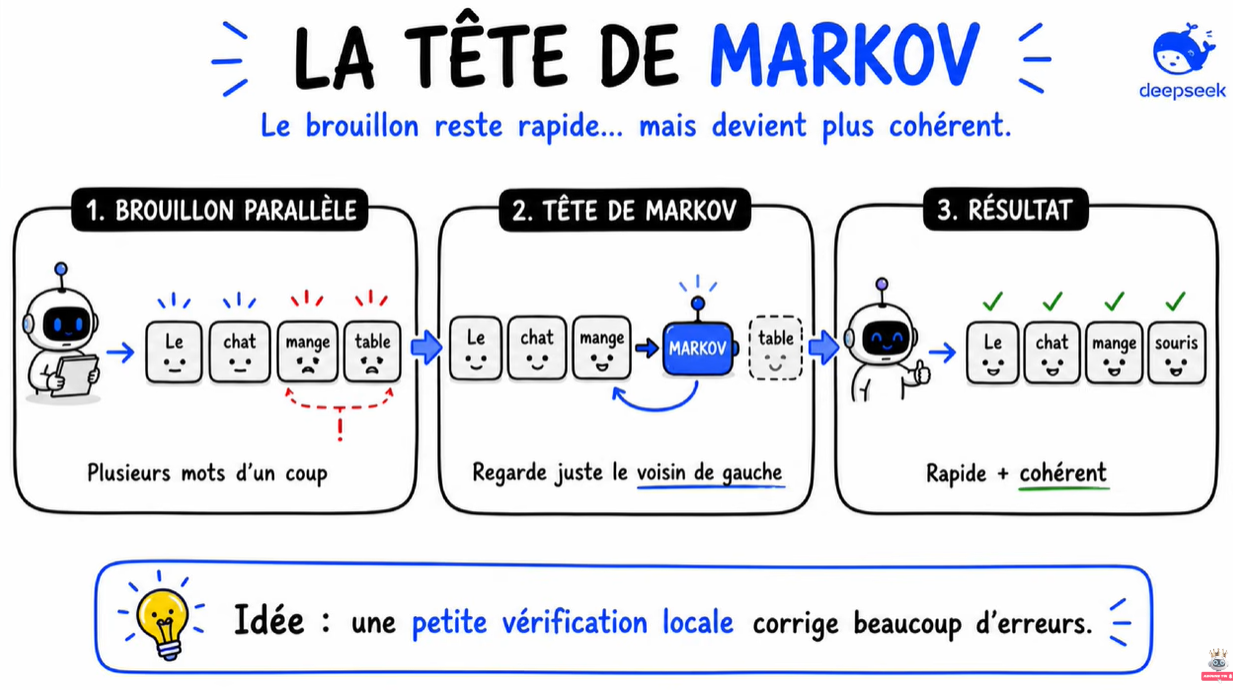
Son rôle est très simple : pour chaque mot, elle regarde seulement le mot juste avant. Pas toute la phrase, pas tout le contexte, juste le voisin de gauche.
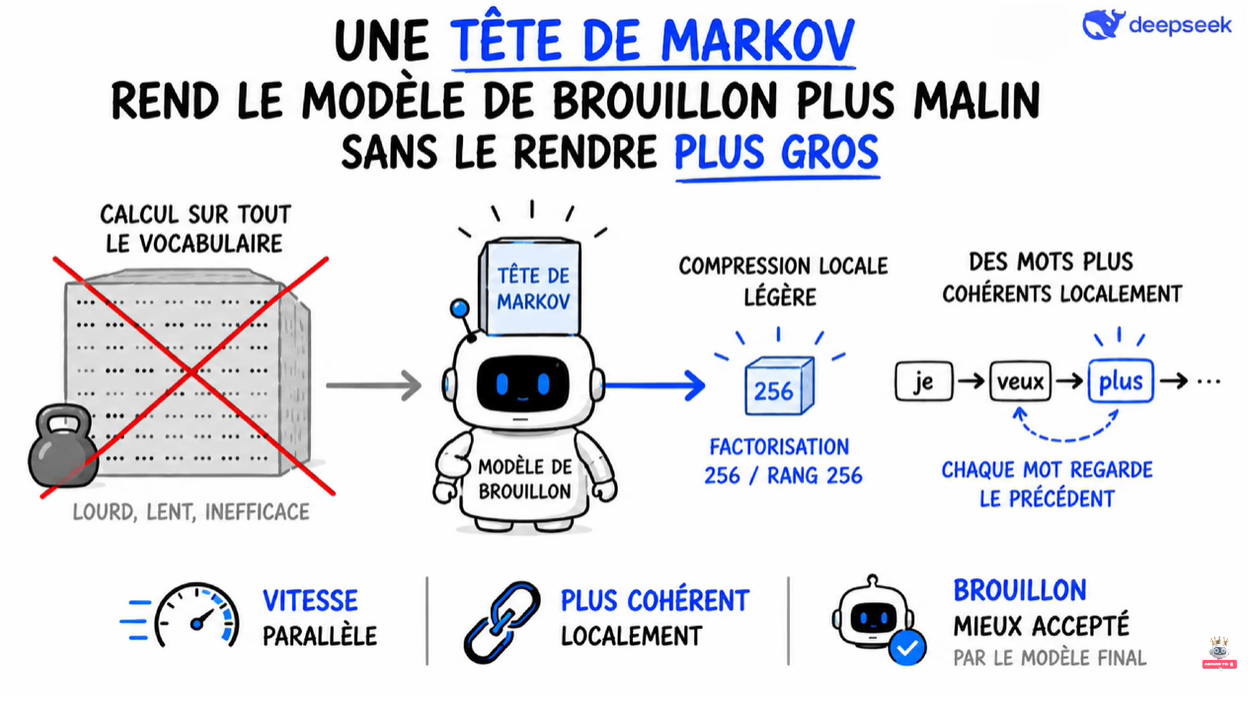
📊 Vérifier plus intelligemment
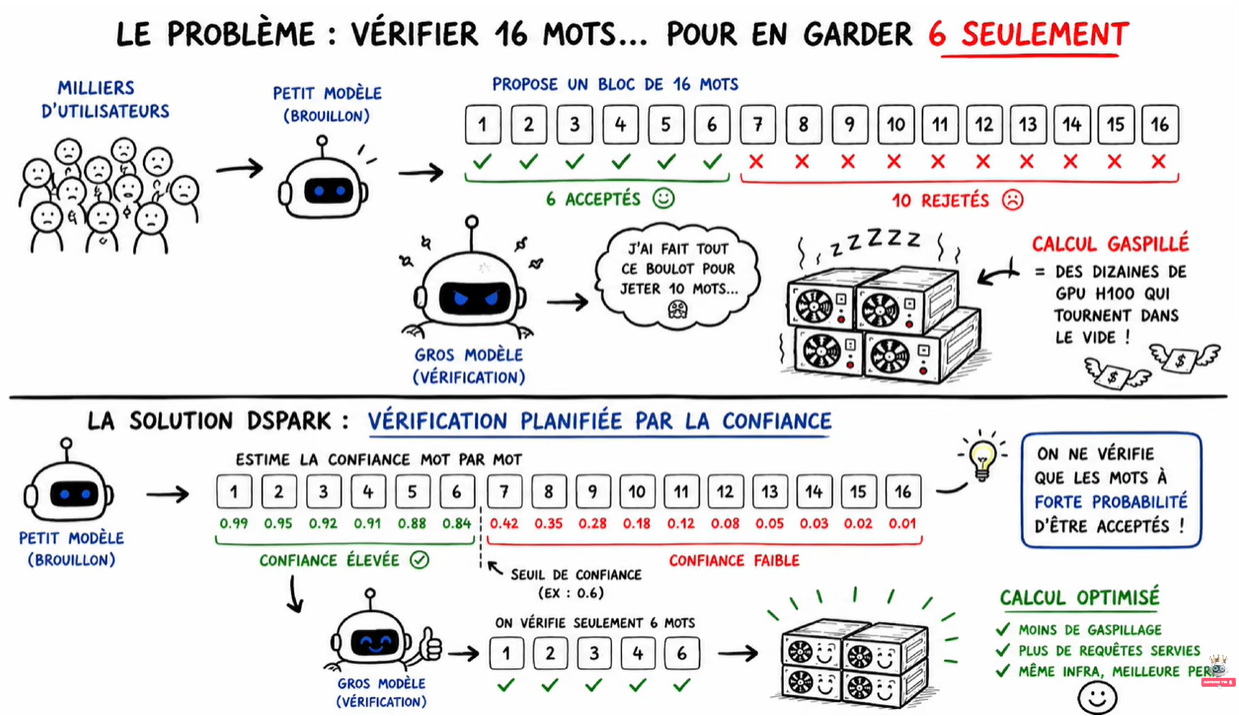
La solution de DSpark : la vérification planifiée par la confiance.
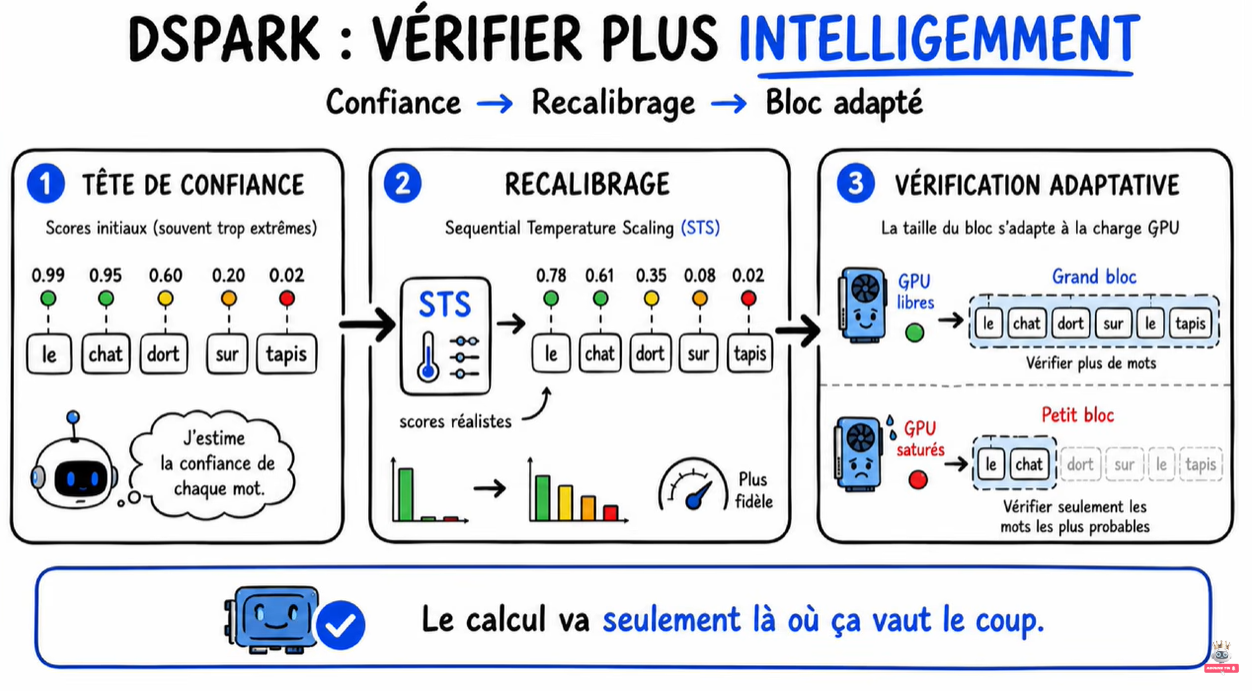
- Tête de confiance : un score pour chaque mot du brouillon.
- Recalibrage : Sequential Temperature Scaling (STS) – l’erreur de calibration passe de 3-8 % à environ 1 %.
- Vérification adaptative : la taille du bloc s’adapte à la charge GPU. Quand ils sont libres, on vérifie de gros blocs. Quand le système est saturé, on raccourcit le bloc.
📈 Performances en production – des chiffres explosés

- DeepSeek V4 Pro : +57 à 78 % de vitesse de génération par utilisateur.
- DeepSeek V4 Flash : +60 à 85 % de vitesse.
- Aucune dégradation de la qualité des réponses (mathématiquement prouvé “lossless”).
- Le débit global du système ne baisse pas sous charge.
- Sur Qwen 3-4B, DSpark accepte 26 à 31 % de mots en plus que Eagle3, et 16 à 18 % de plus que DFlash.
🔓 DeepSeek open source – DeepSpec
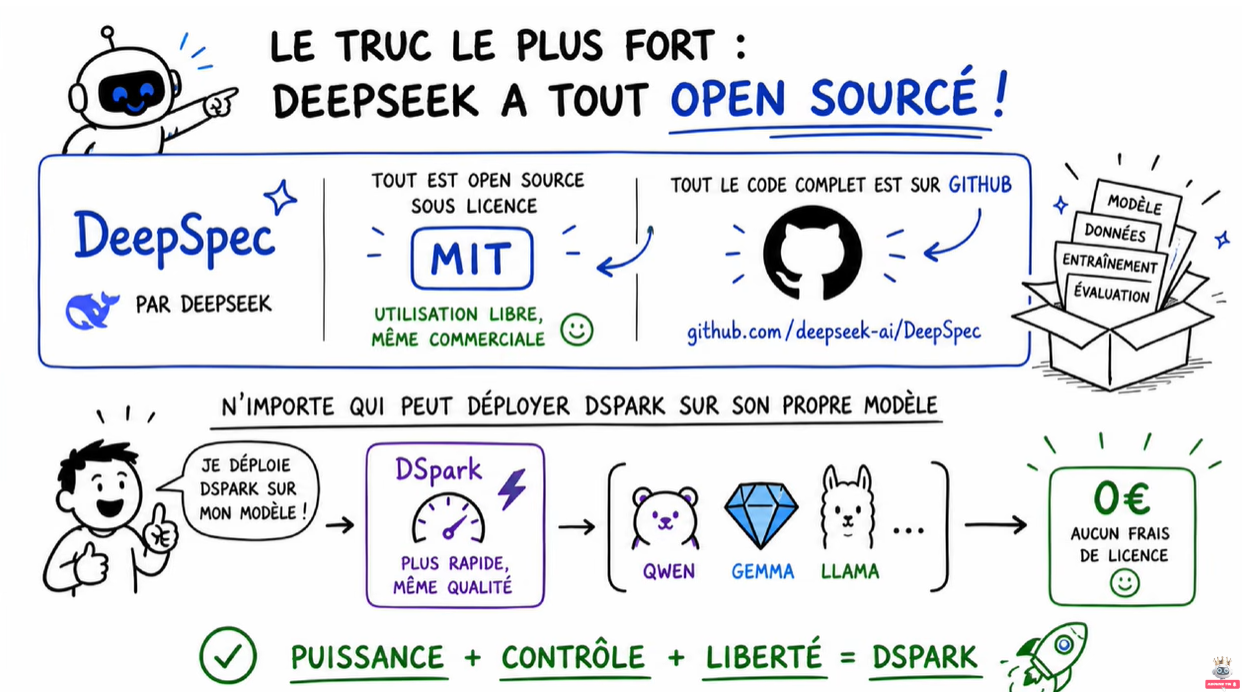
- MIT : utilisation libre, même commerciale.
- Code complet : préparation des données, entraînement, évaluation.
- N’importe qui peut déployer DSpark sur son propre modèle (Qwen, Gemma, Llama).
- Aucun frais de licence.
🧭 La stratégie DeepSeek – étape par étape
💥 DeepSeek détruit la marge commerciale des labos occidentaux
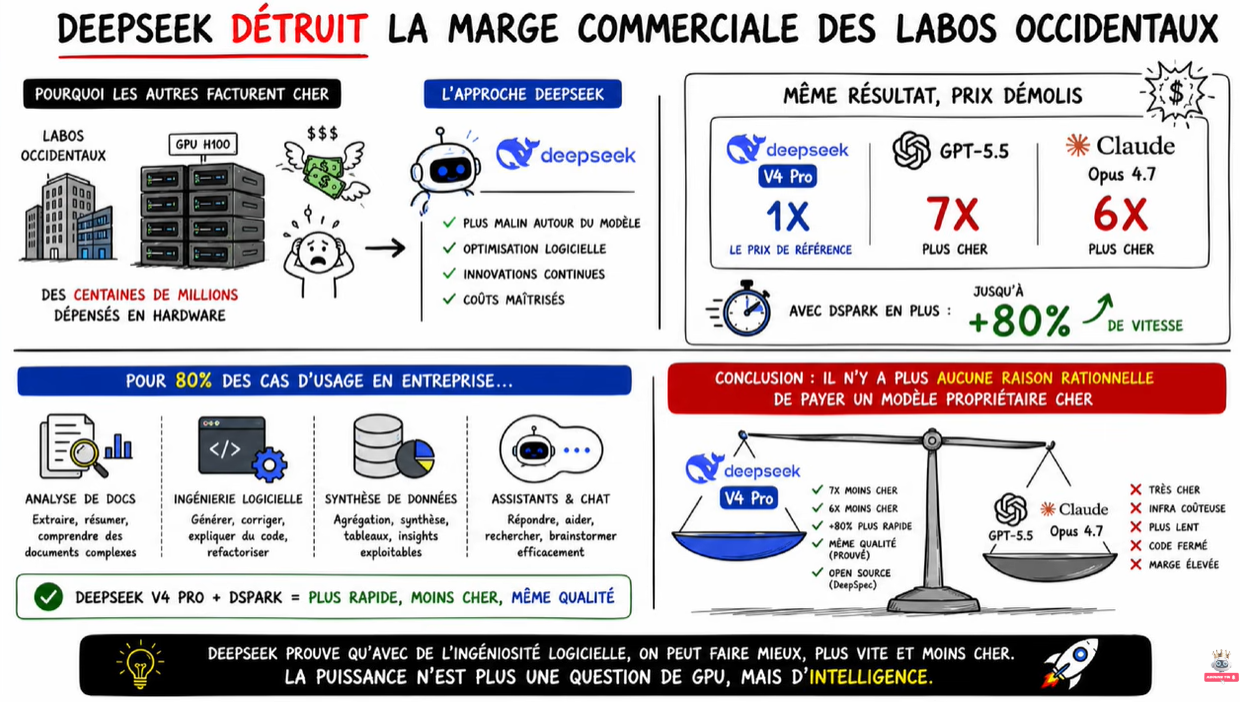
Pour 80 % des cas d’usage en entreprise (analyse de docs, ingénierie logicielle, synthèse de données, assistants & chat), il n’y a plus aucune raison rationnelle de payer un modèle propriétaire cher.
- DeepSeek V4 Pro : 7× moins cher que GPT-5.5, 6× moins cher que Claude Opus 4.7.
- Avec DSpark : +80 % plus rapide.
- Open source : liberté totale, communauté en hyper-croissance.
⚠️ Les angles morts de DeepSeek V4 Pro

1. Tâches agentiques longues
- Terminal-Bench 2.0 : l’agent doit compiler du code, configurer des serveurs, entraîner des modèles sur plusieurs heures.
- DeepSeek V4 Pro : 67,9 %
- GPT-5.5 : 82,7 %
- 15 points d’écart – c’est massif.
2. Hallucinations factuelles
- DeepSeek V4 Pro : 94 % de taux d’hallucination.
- Quasiment chaque fois, il préfère inventer plutôt qu’admettre son ignorance.
- Juridique, médical, factuel critique – ce modèle n’est pas le bon choix.
🌍 Le marché de l’IA se divise

- Modèles propriétaires (GPT-6, Opus 5, Gemini Ultra) :
- Autonomie agentique extrême.
- Zéro hallucination médicale.
- Multimodalité fine.
- Peu d’usages, très exigeants, prix élevés.
- Écosystème DeepSeek :
- Pour tout le reste – mieux, moins cher, plus rapide.
- Analyse de docs, ingénierie logicielle, synthèse de données, assistants & chat, éducation & création.
- Coûts : ÷7 vs modèles propriétaires.
- Vitesse : ×2 avec DSpark.
- Open source : liberté totale, communauté en hyper-croissance.
👁️ Pendant que tout le monde regarde ailleurs, DeepSeek joue un autre jeu

- Coûts d’inférence : divisés par 7.
- Vitesse de génération : multipliée par ~2.
- Et tout ça : gratuitement, open source, transparent, pour une innovation collective.
📘 À propos de cette page
Synthèse illustrée du framework DSpark de DeepSeek – décodage spéculatif, tête de Markov, vérification par confiance, performances, open source, angles morts et positionnement sur le marché de l’IA.